Spark에서 정형 데이터를 사용하기 위해 가장 일반적으로 사용되는 데이터 구조는 Spark SQL 라이브러리의 일부로 제공되는 데이터 프레임입니다. Spark의 데이터 프레임은 유비쿼터스 Pandas Python 라이브러리의 데이터 프레임과 비슷하지만 Spark의 분산 처리 환경에서 작동하도록 최적화되었습니다.
1. 데이터 프레임에 데이터 로드
먼저 레이크하우스에 첨부된 products.csv파일을 업로드하여 새로운 데이터를 가져옵니다.
레이크하우스에 데이터 가져오는 방법은 아래 포스팅을 참고합니다.
2024.01.23 - [Microsoft Fabric/Fabric 실습 시리즈 1] - 05. Fabric 레이크하우스에 데이터 수집하기

1-1. 데이터 조회하기
Spark Notebook에서 다음 PySpark 코드를 사용하여 파일 데이터를 데이터 프레임에 로드하고 처음 10개 행을 표시할 수 있습니다.
레이크하우스 화면 상단의 "전자 필기장 열기"를 클릭하여 "새 Notebook"을 클릭합니다.

"+ 코드"를 클릭하여 새 코드 셀을 추가하고 아래의 pyspark 코드를 입력합니다.

%%pyspark
df = spark.read.load('Files/data/products.csv',
format='csv',
header=True
)
display(df.limit(10))
코드 셀 왼쪽의 실행 버튼 ▷ 을 클릭하거나 키보드에서 shift + Enter를 치면 코드가 실행이 되고 해당 파일 데이터의 처음 10개행을 표시할 수 있습니다.

1-2. 데이터 프레임 필터링 및 그룹화
Dataframe 클래스의 메서드를 사용하여 포함된 데이터를 필터링, 정렬, 그룹화 또는 조작할 수 있습니다. 예를 들어 다음 코드 예제에서는 select 메서드를 사용하여 이전 예제의 제품 데이터가 포함된 df 데이터 프레임에서 ProductID 및 ListPrice 열을 검색합니다.
pricelist_df = df.select("ProductKey", "ListPrice")
display(pricelist_df.limit(5))
Datafram에서 열을 선택하는 코드는 더 간단히 아래와 같이 작성할 수도 있습니다.
pricelist_df = df["ProductKey", "ListPrice"]
이번에는 select와 where메서드를 연결하여 Mountain Bikes 또는 Road Bikes 서브카테고리의 ProductName 및 ListPrice 열을 포함하는 새 데이터 프레임을 만들어 봅니다.
bikes_df = df.select("ProductName", "SubCategory", "ListPrice").where((df["SubCategory"]=="Mountain Bikes") | (df["SubCategory"]=="Road Bikes"))
display(bikes_df)
데이터를 그룹화하고 집계하려면 groupBy 메서드 및 집계 함수를 사용할 수 있습니다. 예를 들어 다음 PySpark 코드는 각 서브카테고리의 제품 수를 계산합니다.
counts_df = df.select("ProductKey", "SubCategory").groupBy("SubCategory").count()
display(counts_df)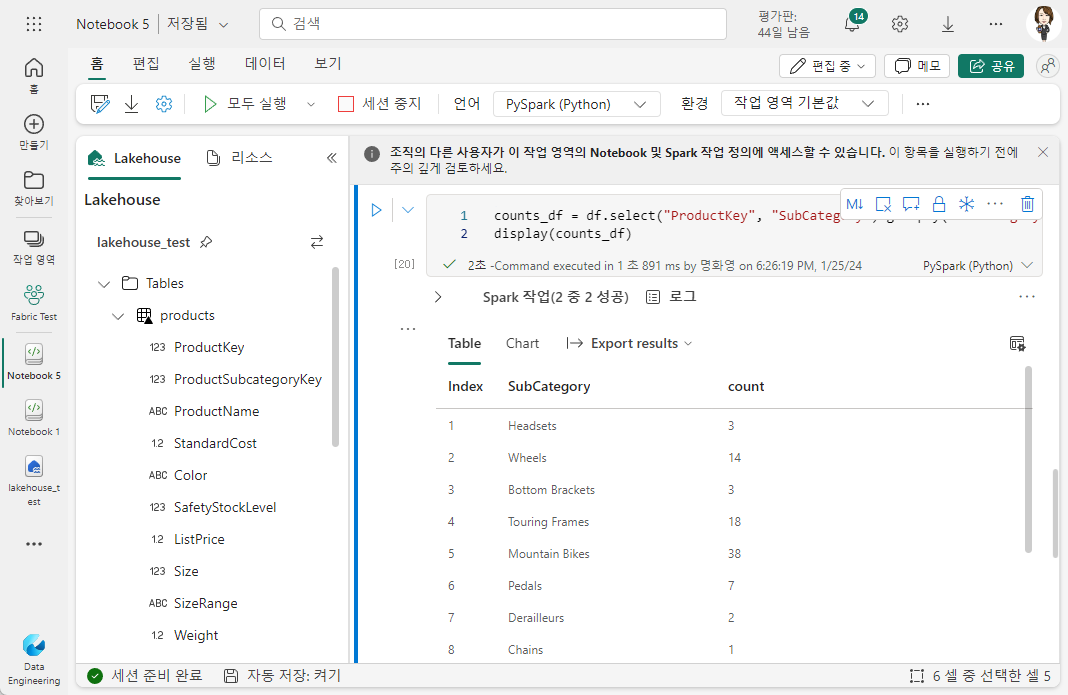
2. 데이터 프레임 저장
Spark를 사용하여 원시 데이터를 변환하고 추가 분석 또는 다운스트림 처리를 위해 결과를 저장하려고 합니다. 다음 코드 예제에서는 dataFrame을 데이터 레이크의 parquet 파일에 저장하여 동일한 이름의 기존 파일을 대체합니다.
bikes_df.write.mode("overwrite").parquet('Files/product_data/bikes.parquet')
코드 셀을 실행하고 브라우저를 새로고침 해보면 Files 아래 product_data 하위 폴더가 생성되고 하위 폴더 아래 bike.parquet 데이터가 만들어진 것을 볼 수 있습니다.

2-1. Output 파일 분할
분할은 Spark가 작업자 노드에서 성능을 극대화할 수 있도록 하는 최적화 기술입니다. 불필요한 디스크 IO를 제거하여 쿼리에서 데이터를 필터링할 때 성능을 더 많이 향상할 수 있습니다.
데이터 프레임을 분할된 파일 집합으로 저장하려면 데이터를 작성할 때 partitionBy 메서드를 사용합니다. 다음 예제에서는 bikes_df 데이터 프레임( Mountain Bikes 또는 Road Bikes 서브카테고리에 대한 제품 데이터 포함)을 저장하고 범주별로 데이터를 분할합니다.
bikes_df.write.partitionBy("SubCategory").mode("overwrite").parquet("Files/bike_data")
데이터 프레임을 분할할 때 생성된 폴더 이름에는 column=value 형식의 분할 열 이름과 값이 포함되므로 코드 예제에서는 다음 하위 폴더가 포함된 bike_data 폴더를 만듭니다.
- SubCategory=Mountain Bikes
- SubCategory=Road Bikes
2-2. 분할된 데이터 로드
분할된 데이터를 데이터 프레임으로 읽을 때 분할된 필드의 명시적 값 또는 와일드카드를 지정하여 계층 구조 내의 폴더에서 데이터를 로드할 수 있습니다. 다음 예제에서는 Road Bikes 범주의 제품에 대한 데이터를 로드합니다.
road_bikes_df = spark.read.parquet('Files/bike_data/SubCategory=Road Bikes')
display(road_bikes_df.limit(5))
분할에 사용된 SubCategory열은 결과 dataframe 에서 생략됩니다.
'Microsoft Fabric > Fabric 실습 2 - Spark' 카테고리의 다른 글
| 06. Apache Spark로 데이터 분석 연습하기 (0) | 2024.01.30 |
|---|---|
| 05. Spark Notebook에서 데이터 시각화 (0) | 2024.01.30 |
| 04. Spark SQL을 사용하여 데이터 작업 (0) | 2024.01.30 |
| 02. Spark 코드 실행하기 (0) | 2024.01.25 |
| 01. Apache Spark 사용 설정하기 (0) | 2024.01.25 |



