1. Delta Lake 이해
Delta Lake는 Spark 기반 데이터 레이크 처리에 관계형 데이터베이스 의미 체계를 추가하는 오픈 소스 스토리지 계층입니다. Microsoft Fabric 레이크하우스의 테이블은 Delta 테이블로, 레이크하우스 사용자 인터페이스의 테이블에 있는 삼각형 Delta(▴) 아이콘으로 표시됩니다.

Delta 테이블은 Delta 형식으로 저장된 데이터 파일에 대한 스키마 추상화입니다.
각 테이블에 대해 레이크하우스는 Parquet 데이터 파일이 포함된 폴더와 트랜잭션 세부 정보가 JSON 형식으로 기록되는 _delta_Log 폴더를 저장합니다.
Delta 테이블을 사용하면
- 쿼리 및 데이터 수정을 지원하는 관계형 테이블. Apache Spark를 사용하면 CRUD(만들기, 읽기, 업데이트, 삭제) 작업을 지원하는 Delta 테이블에 데이터를 저장할 수 있습니다. 즉, 관계형 데이터베이스 시스템에서와 동일한 방식으로 데이터 행을 선택, 삽입, 업데이트 및 삭제할 수 있습니다.
- ACID 트랜잭션 지원. 관계형 데이터베이스는 원자성(트랜잭션이 단일 작업 단위로 완료됨), 일관성(트랜잭션이 데이터베이스를 일관된 상태로 유지), 격리(프로세스 내 트랜잭션이 서로 간섭할 수 없음), 내구성(트랜잭션이 완료되면 해당 변경 내용이 유지됨)을 제공하는 트랜잭션 데이터 수정을 지원하도록 설계되었습니다. Delta Lake는 트랜잭션 로그를 구현하고 동시 작업에 직렬화 가능한 격리를 적용하여 Spark에 이와 동일한 트랜잭션 지원을 제공합니다.
- 데이터 버전 관리 및 시간 이동. 모든 트랜잭션이 트랜잭션 로그에 로그되므로 각 테이블 행의 여러 버전을 추적하고 시간 이동 기능을 사용하여 쿼리에서 이전 버전의 행을 검색할 수도 있습니다.
- 일괄 처리 및 스트리밍 데이터 지원. 대부분의 관계형 데이터베이스에는 정적 데이터를 저장하는 테이블이 포함되지만 Spark에는 Spark 구조적 스트리밍 API를 통한 스트리밍 데이터에 대한 기본 지원이 포함됩니다. Delta Lake 테이블은 스트리밍 데이터의 싱크(대상) 및 원본으로 사용할 수 있습니다.
- 표준 형식 및 상호 운용성. Delta 테이블의 기본 데이터는 데이터 레이크 수집 파이프라인에서 일반적으로 사용되는 Parquet 형식으로 저장됩니다. 또한 Microsoft Fabric Lakehouse에 대한 SQL 분석 엔드포인트를 사용하여 SQL에서 델타 테이블을 쿼리할 수 있습니다.
2. 테이블 메타데이터 만들기
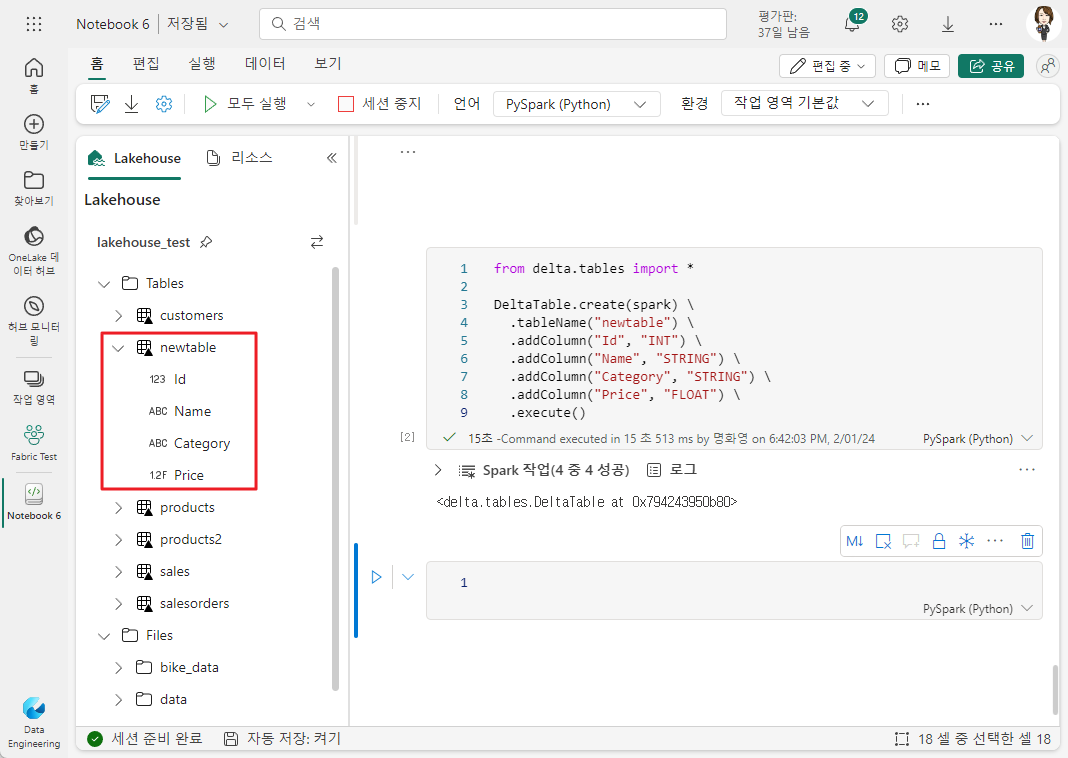
2-1. DeltaTableBuilder API 사용
DeltaTableBuilder API를 사용하면 Spark 코드를 작성하여 사양에 따라 테이블을 만들 수 있습니다.
from delta.tables import *
DeltaTable.create(spark) \
.tableName("newtable") \
.addColumn("Id", "INT") \
.addColumn("Name", "STRING") \
.addColumn("Category", "STRING") \
.addColumn("Price", "FLOAT") \
.execute()
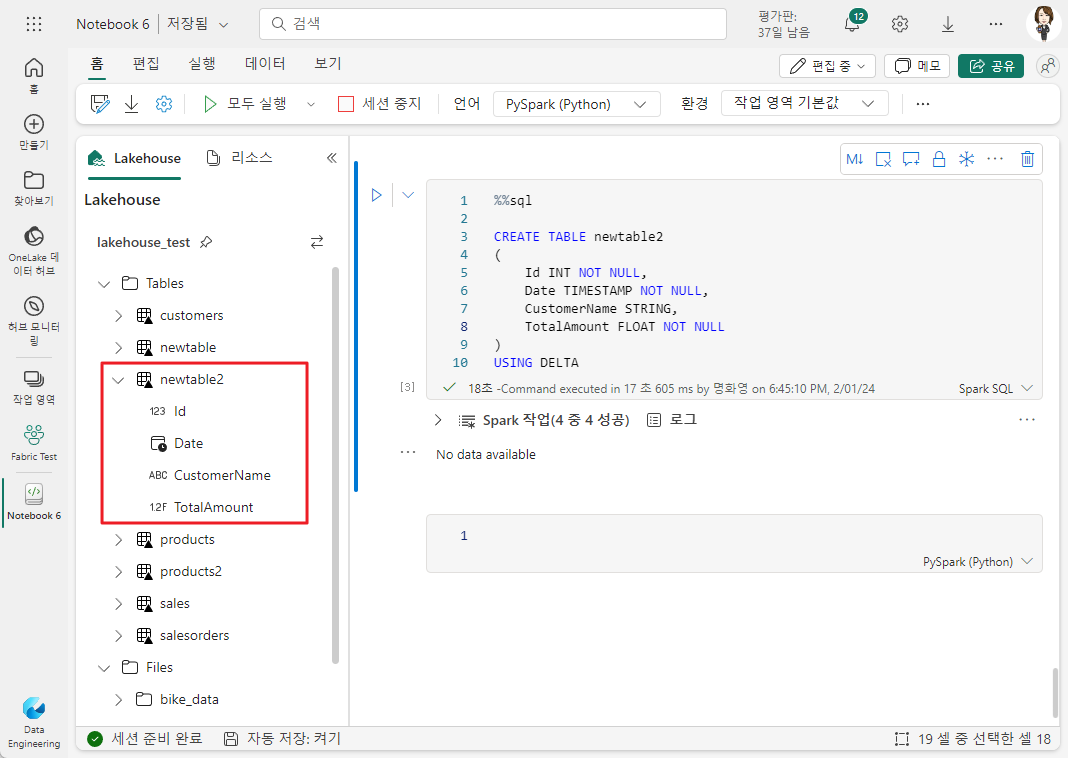
2-2. Spark SQL 사용
%%sql
CREATE TABLE newtable2
(
Id INT NOT NULL,
Date TIMESTAMP NOT NULL,
CustomerName STRING,
TotalAmount FLOAT NOT NULL
)
USING DELTA
델타 형식으로 데이터 저장
델타 형식으로 데이터를 저장하는 방식은 나중에 Delta Lake API를 사용하여 테이블 정의 또는 프로세스를 직접 “오버레이”할 수 있는 파일 형식으로 Spark에서 수행된 데이터 변환 결과를 유지하려는 경우에 유용할 수 있습니다.
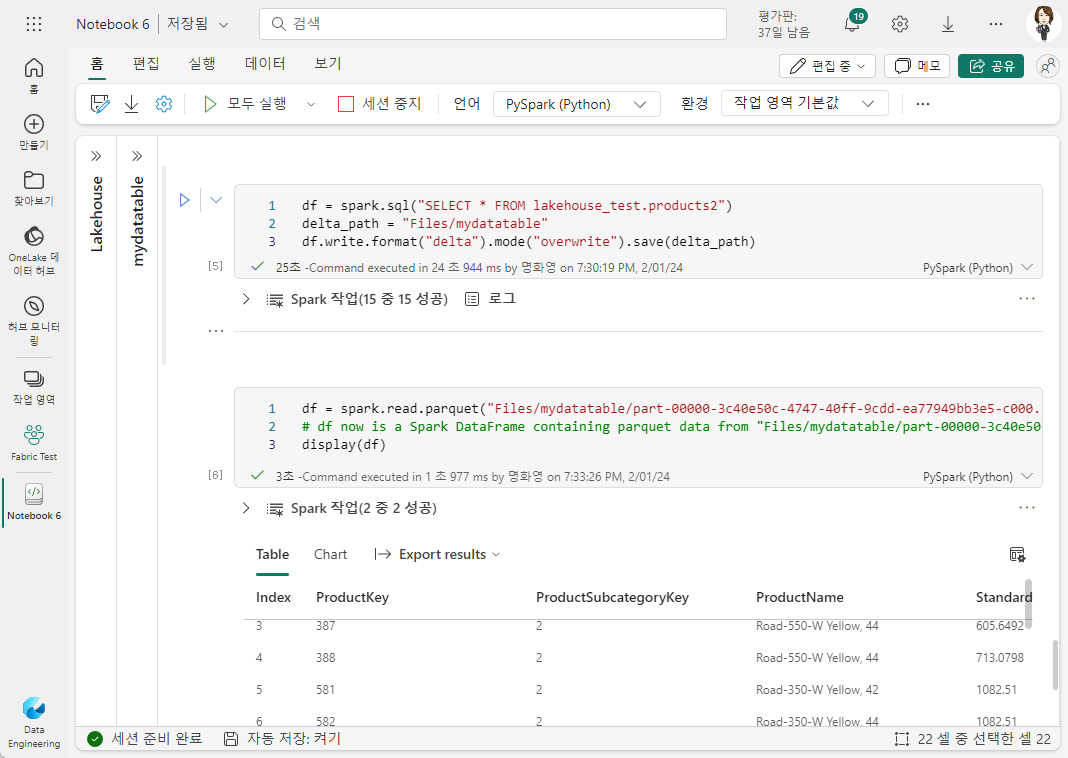
아래 Pyspark 코드는 Tables의 products2 테이블 데이터프레임을 델타 형식으로 새 폴더(mydatatable)에 저장합니다.
df = spark.sql("SELECT * FROM lakehouse_test.products2")
delta_path = "Files/mydatatable"
df.write.format("delta").save(delta_path)
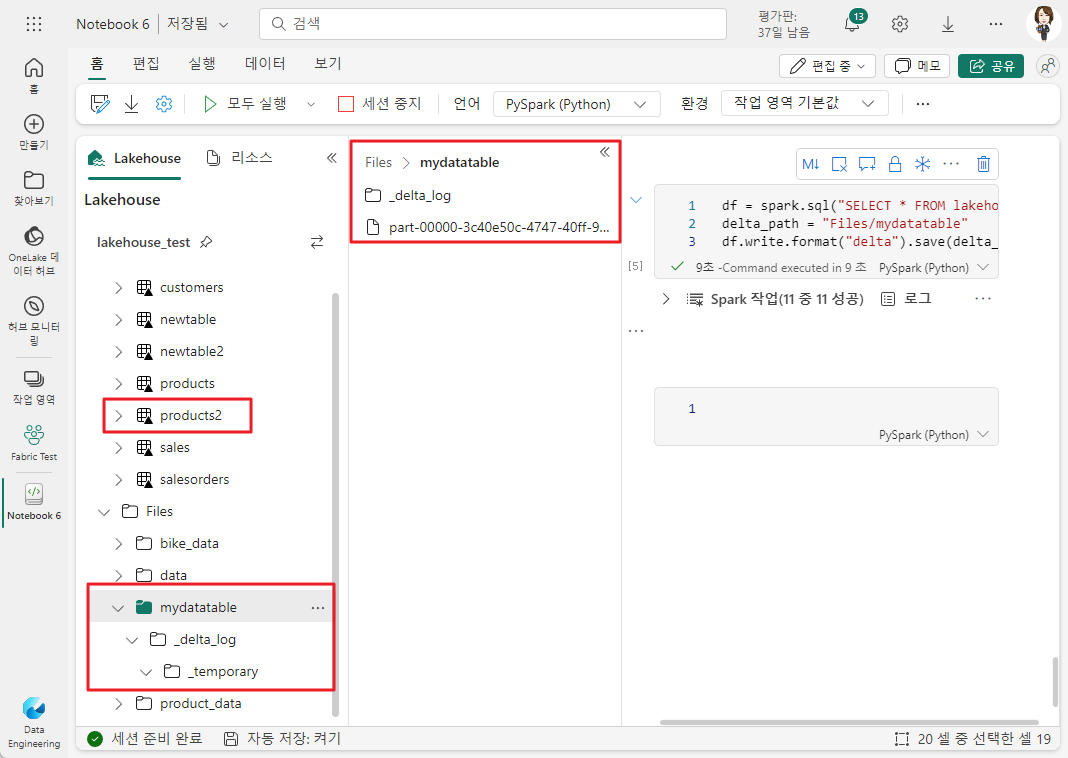
Files 아래에 새로 생긴 폴더에는 데이터가 포함된 Parquet 파일과 데이터 트랜젝션 로그가 포함된 _delta_log 폴더가 생깁니다.
그리고 overwrite 모드를 사용하여 기존 폴더의 콘텐츠를 데이터 프레임의 데이터로 바꿀 수 있습니다.
'Microsoft Fabric > Fabric 실습 1 - Lakehouse' 카테고리의 다른 글
| 08. 스트리밍 데이터에 델타 테이블 사용 (0) | 2024.02.06 |
|---|---|
| 07. Spark에서 델타 테이블 작업 (0) | 2024.02.06 |
| 05. 레이크하우스에서 보고서 만들기 (0) | 2024.01.24 |
| 04. 레이크하우스에서 시각적 쿼리 만들기 (0) | 2024.01.23 |
| 03. 레이크하우스에서 SQL 쿼리 사용하기 (0) | 2024.01.23 |



