델타 테이블(또는 델타 형식 파일)을 사용하여 여러 가지 방법으로 데이터를 검색하고 수정할 수 있습니다.
Spark SQL 사용
Spark의 델타 테이블에서 데이터를 다루는 가장 일반적인 방법은 Spark SQL을 사용하는 것입니다. spark.sql 라이브러리를 사용하여 다른 언어(예: PySpark 또는 Scala)에 SQL 문을 포함할 수 있습니다.
이전 포스팅에서 생성된 newtable 테이블에 행을 추가해봅니다.
2024.01.30 - [Microsoft Fabric/Fabric 실습 시리즈 1] - 15. Fabric의 Delta Lake
spark.sql("INSERT INTO newtable VALUES (1, 'Widget', 'Accessories', 2.99)")
Spark 작업 성공 후 newtable 테이블을 로드해 보면 행이 하나 추가된 것을 확인할 수 있습니다.

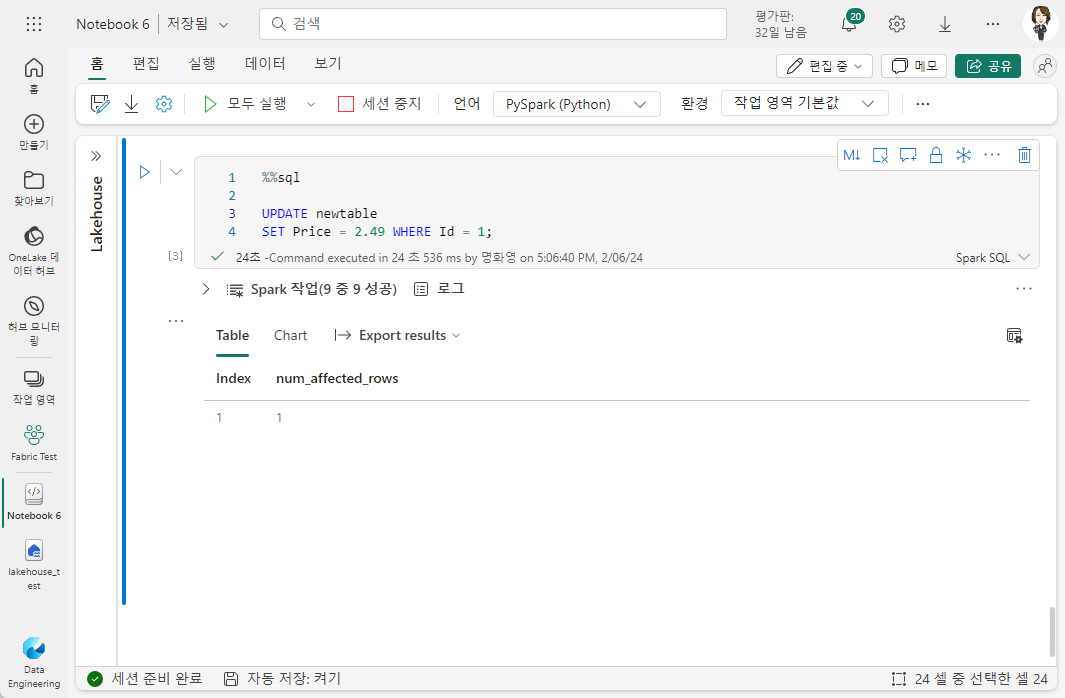
%%sql 매직을 사용해서 행 업데이트를 다음과 같이 할 수 있습니다.
%%sql
UPDATE newtable
SET Price = 2.49 WHERE Id = 1;
Delta API 사용
델타 파일로 작업하려는 경우 Delta Lake API를 사용하는 것이 더 간단할 수 있습니다.
from delta.tables import *
from pyspark.sql.functions import *
# DeltaTable 오브젝트 생성하기
delta_path = "Files/mydatatable"
deltaTable = DeltaTable.forPath(spark, delta_path)
# 데이터 업데이트 (Mountain Bikes SubCategory만 10% 감소)
deltaTable.update(
condition = "SubCategory == 'Mountain Bikes'",
set = { "ListPrice": "ListPrice * 0.9" })

테이블 버전 관리 작업
델타 테이블에 대한 수정 사항은 테이블의 트랜잭션 로그에 기록됩니다.
테이블의 기록을 보려면 다음과 같이 DESCRIBE SQL 명령을 사용할 수 있습니다.
%%sql
DESCRIBE HISTORY newtable

외부 테이블의 기록을 보려면 테이블 이름 대신 폴더 위치를 지정할 수 있습니다.
%%sql
DESCRIBE HISTORY 'Files/mydatatable'

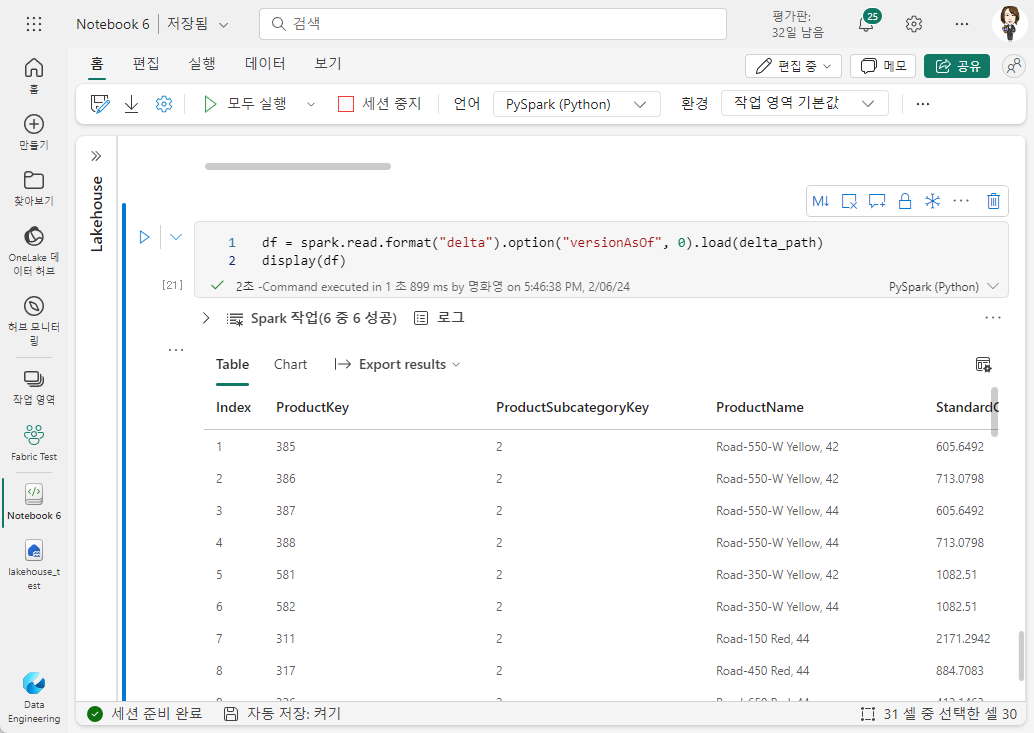
델타 파일 위치를 데이터 프레임으로 읽고 필요한 버전을 versionAsOf 옵션으로 지정하여 특정 버전의 데이터에서 데이터를 검색할 수 있습니다.
df = spark.read.format("delta").option("versionAsOf", 0).load(delta_path)
display(df)
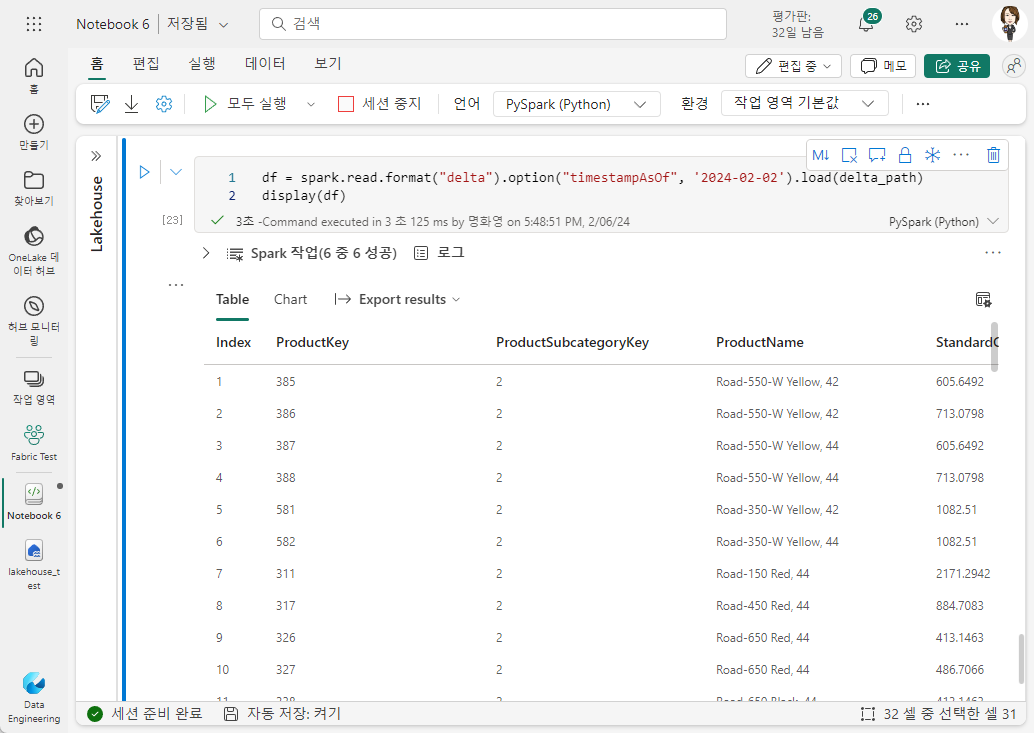
또는 timestampAsOf 옵션을 사용하여 타임스탬프를 지정할 수 있습니다.
df = spark.read.format("delta").option("timestampAsOf", '2024-02-02').load(delta_path)
display(df)
'Microsoft Data & AI > Fabric 실습 1 - Lakehouse' 카테고리의 다른 글
| 08. 스트리밍 데이터에 델타 테이블 사용 (1) | 2024.02.06 |
|---|---|
| 06. Fabric의 Delta Lake (0) | 2024.01.30 |
| 05. 레이크하우스에서 보고서 만들기 (0) | 2024.01.24 |
| 04. 레이크하우스에서 시각적 쿼리 만들기 (0) | 2024.01.23 |
| 03. 레이크하우스에서 SQL 쿼리 사용하기 (0) | 2024.01.23 |



